- Web Developer
- Posts
- Memory Management Every Developer Should Know
Memory Management Every Developer Should Know
What data is put on the stack and what data is put on the heap?
Zachary Lee
May 05, 2024
This article explores a crucial aspect of programming: memory management. You might have a vague idea about it or often overlook it. We'll focus on high-level memory management abstractions, which may prove useful if you're looking to understand memory management from a broader perspective, especially as a web developer.
Question
Let me ask you a question first:
What data is put on the stack and what data is put on the heap?
If you are good at languages with automatic memory management such as JavaScript/Python/Java, you might say the following answer:
Primitive types are stored on the stack, objects are stored on the heap, closure variables are stored on the heap, and so on.
Is this answer correct? No problem, but this is only the surface, not the essence. So what is the essence?
Let’s first analyze the stack and heap in the program, and then give the answer.
Stack
The stack data structure is characterized by first-in, last-out. Because of this feature, it is very suitable for recording the function calls of the program, which is also called the function call stack. Then take a look at the following simple code example:
fn test() {}
fn main() {
test()
}Let’s analyze it. First, the code we write will be executed as an “entry”. Please see the following diagram:
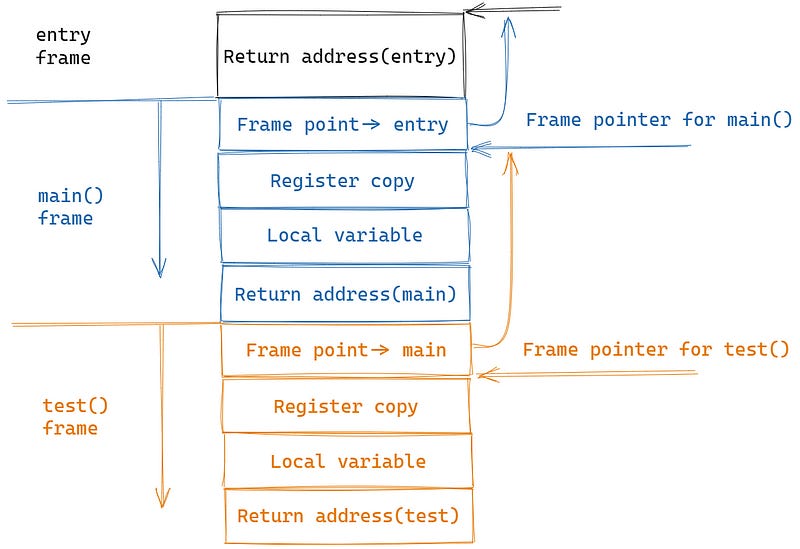
The function call stack grows from top to bottom. In this simple code example, the call flow is entry -> main() -> test().
Next, whenever a function executes, a contiguous piece of memory is allocated at the top of the stack, which is called a frame.
This “frame” stores the context information of the current function’s general-purpose registers and the current function’s local variables.
In this example, when main() calls test(), it will temporarily interrupt the current CPU execution process, and store a copy of the main() general-purpose register in the stack. After the test() is executed, the original register context will be restored according to the previous copy, as if nothing had happened.
Then, as the function is called layer by layer, the stack will expand layer by layer, and after the call ends, the stack will backtrack layer by layer, and the memory occupied by each frame will be released one by one.
But wait, we seem to be missing something. In usual circumstances, it requires contiguous memory space, which means that the program must know how much memory space the next function needs before calling the next function.
So how does the program know?
The answer is that the compiler does it all for us.
When compiling code, a function is the smallest compilation unit. Whenever the compiler encounters a function, it knows the space required by the current function to use registers and local variables.
Therefore, data whose size cannot be determined at compile time or whose size can be changed cannot be safely placed on the stack.
Heap
As mentioned above, that data cannot be safely placed on the stack, so it is better to put it on the heap, such as the following variable-length array:

When creating an array without specifying its length, the program needs to dynamically allocate memory. For example, in C, this is typically done using the malloc() function. Initially, a certain amount of space is reserved (for instance, space for 4 elements might be reserved in Rust). If the actual usage of the array exceeds this capacity, the program allocates a larger memory block, copies the existing elements into it, adds the new elements, and then frees the old memory. This process allows the array to dynamically resize as needed.
The process of requesting system calls and finding new memory and then copying it one by one is very inefficient.
So the best practice here is to reserve the space that the array really needs in advance.
In addition, the memory that needs to be referenced across the stack also needs to be placed on the heap, which is well understood because once a stack frame is reclaimed, its internal local variables will also be reclaimed, so sharing data in different call stacks can only use the heap.
But this brings up a new question, when will the memory occupied on the heap be released?
Garbage collection
The major programming languages have given their answers:
The early C language left all this to developers to manage manually, which is an edge for experienced programmers because of the finer control over the program’s memory. But for those who are beginners, it is important to keep in mind those best practices for memory management. But unlike machines, there can always be some oversights, which can lead to memory safety issues, resulting in programs running slowly or crashing outright.
A series of programming languages represented by Java use Tracing GC (Tracing Garbage Collection) to automatically manage heap memory. This approach takes the burden off the developer by automatically managing memory by periodically marking objects that are no longer referenced and then cleaning them up. But it needs to perform extra logic when marking and freeing memory, which causes STW (Stop The World), like the program gets stuck, and those times are also indeterminate. Therefore, if you want to develop some systems with high real-time requirements, GC-like languages are generally not used.
Apple’s Objective-C and Swift use ARC (Automatic Reference Counting), which inserts retain/release statements for each function at compile time to automatically maintain the reference count of objects on the heap. When an object’s reference count is 0, the release statement can release the object. But it adds a lot of extra code to handle reference counting, making it less efficient and less throughput than GC.
Rust uses the ownership mechanism, which binds the life cycle of the data on the heap and the life cycle of the stack frame by default. Once the stack frame is destroyed, the data on the heap will also be discarded, and the occupied memory will be released. And Rust also provides APIs for developers to change this default behavior or customize the behavior on release.
Conclusion
The data stored on the stack is static, of fixed size, and a fixed life cycle, and cannot be referenced across the stack.
The data stored on the heap is dynamic, not fixed size, not fixed life cycle, and can be referenced across stacks.
If you find this helpful, please consider subscribing for more useful articles and tools about web development. Thanks for reading!